
Accidentally Quadratic: Evaluating trillions of event matches in real-time
Building the expression engine that powers ephemeral event matching.
Tony Holdstock-Brown · 5/15/2024 · 10 min read
Event-driven systems depend on accurately matching and filtering events. This process ensures data is directed to the right part of the code that needs specific event information. Systems like Kafka offer topics and filters to allow consumers to achieve this, but they need to be determined up front either at the infrastructure level or directly in the code. This is great, but what about in a multi-tenant system where you don't know what event types or filters you might need up front?
With Inngest, we allow developers to build event-driven functions that are able to filter over millions of events. Developers can also define short-lived event matching statements that might exist for seconds or weeks. Our goal is to offer the flexibility of filtering and matching of event-driven systems like Kafka without all of the work of managing or optimizing the system itself.
Dynamic Event Filtering
This is the core of the challenge that we have with Inngest. Inngest allows developers to create event-driven functions that can wait for additional events that match specific filter expressions, or declare that functions should automatically be be cancelled by specific events. The hard part is abstracted away from the developer with a line of code.
As an example, this code allows the developer to pause a function in the middle of execution to wait for an app/onboarding.completed event with a payload that matches the value of the data.userId exactly:
jsconst onboardingCompleted = await step.waitForEvent("wait-for-onboarding-completion",{event: "app/onboarding.completed",timeout: "3d",if: `data.userId == '${user.id}'`});
While this looks very simple, this matching expression is created dynamically at runtime, so under the hood, the system must quickly update the internal event stream consumers to evaluate all events for a potential match. We run a multi-tenant system, so each event needs to be evaluated against millions of potential matches. Even worse: every run of the function can create a new, unique expression, leading to an explosion of mathing expressions.
This is where the complexity lies, these ephemeral event matchers must be quickly added, evaluated and removed just as quickly. With their short-lived nature, we also can't quite optimize the system with topics and thousands of stream consumers with filtering that spin up and down for each statement.
How would you make this match? You could add these matching expressions to a database and optimize indexes. This might work on a small scale, but that's not what we're dealing with. It works in single-tenant architectures, as expressions are often defined in the code at start time, and the volume is lower.
But when you're talking about evaluating matches tens of thousands of times per second, even the best index in the world falls over. With the ephemeral nature of these matchers, any database might also see performance challenges with constant index rebuilding.
Ephemeral event matching in multi-tenant systems
As Inngest is event-driven, there are two types of event matching that happens in the system.
The first type are long-lived matchers which trigger functions to run. These are mostly generic matchers based on an event name, for example app/user.created.
The second type are ephemeral matchers which only exist during the life of a running function. These matchers contain explicit matching statements that are relevant to the running function itself. For example, if a function is started using the app/user.created event, the function should only be cancelled by an app/user.deleted event with a matching userId.
jsinngest.createFunction({id: "sync-contacts",cancelOn: [{ event: "app/user.deleted", match: "data.userId" }],},{ event: "app/user.created" },// ...);
To visualize how ephemeral event matchers are created and removed through the life of a running function, look at the diagram below:
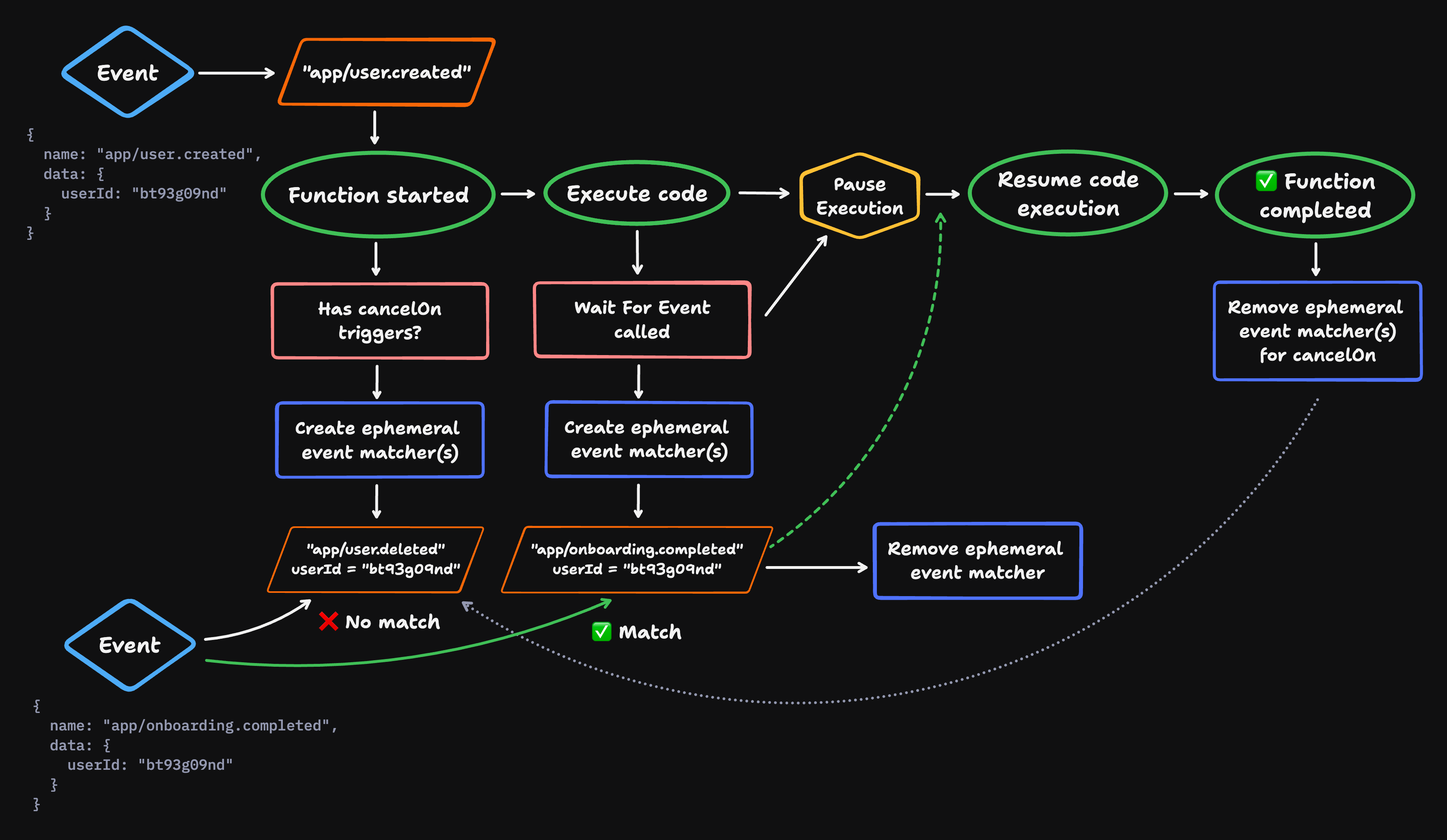
These ephemeral matching statements might be used in various use cases:
- A human-in-the-middle AI workflow that needs to pause and wait for approval to continue execution.
- A function that schedules the publishing of a blog post that must be cancelled if the user updates the status back to a draft.
- A data pipeline that needs to restart (cancel + start again) if data in the source changes.
- An onboarding email campaign that changes depending on if a user does or does not complete a funnel action within a desired time.
All of these types of use cases must be supported so a user can define it in their code, test it locally, ship it to production, and immediately scale it to high volume with milliseconds of latency.
Our Accidentally Quadratic Core Functionality
There are some interesting aspects and optimization for both types of event matching at the core of Inngest, but we'll focus on the most challenging: the ephemeral event triggers.
These are everywhere in Inngest. As we highlighted, they come in the form of waitForEvent and cancelOn expressions. Similar functionality powers our invoke functionality to execute child functions, but we'll focus on the former two.
Within every waitForEvent and cancelOn, we have to match an expression. These expressions can be:
- Simple:
async.data.id == "inng_01HJWB7BXGDV7M33V3PJH84ZC2_1" - Compound:
async.data.env == "NL" && async.data.centerId == "ae4f5871-c3a6-420a-b377-f8ab583c0086" - Complex:
async.data.seller == 'Fantastic Store' && async.data.region == 'GB' && async.data.request.operation == 'reports.getReportDocument' && async.data.amount >= 2000
Here's an example of how this looks in the code:
js// Wait 30 days for a user to start a subscription// on the pro planconst subscription = await step.waitForEvent("wait-for-subscription", {event: "app/subscription.created",timeout: "30d",if: "event.data.userId == async.data.userId && async.data.billing_plan == 'pro'",});
The whole point of Inngest is to deal with events at scale with a good user experience. Our customers push thousands of events every second through Inngest. So, if the above event is called, Inngest has to evaluate that expression, event.data.userId == async.data.userId && async.data.billing_plan == 'pro', against all wait for event or cancel expressions to find a match.
Suddenly, we have a quadratic nightmare.
Say we have 250,000 matching expressions and 250,000 events (the scale that happens with Inngest). You then have 250,000 * 250,000 = 62,500,000,000 expressions to evaluate.
With this number of expressions, evaluating one per millisecond would take two years. This is slightly outside the bounds of the latencies our customers expect. If a user uses Inngest, then event evaluation is mission-critical–these functions must return immediately.
This is a massive issue that kills scaling. At Inngest, we've seen timeouts, CPU spikes, and huge pressure in our data stores, which store and serve expressions. This isn't just mission-critical for customers; it is mission-critical for Inngest. How do we evaluate billions of expressions in real-time?
Do the least amount of work possible.
Ignore Everything (Except The One Thing You Care About)
The only insight that matters is this: A series of expressions must be matched, and one event must match against all expressions. We just need to know and not evaluate the expressions that don't match. If we can cut out the work, then we solve our problem.
To do this, we need to do two things:
- Normalize our expressions and parse them into an abstract syntax tree, then
- Use in-memory indexes (hashmaps, b-trees, ARTs) to look up equalities and find the exact match.
Normalizing Expressions and Building ASTs
An abstract syntax tree (AST) is a hierarchical representation of the code's syntactic structure, where each node corresponds to a variable, expression, or statement.
Using ASTs means we can break down each expression into constituent parts and then traverse only the nodes on the tree that match at each level. We must normalize the expressions before adding them to the tree, as this allows us to cache expression parsing into the tree.
To do this, we lift variables from expressions. For example:
jsevent.data.id == "foo"
and:
jsevent.data.id == "bar"
both become:
jsevent.data.id == vars.a
where vars.a points to a different value (either “foo” or “bar”). We then parse the expressions into ASTs and normalize the AST so that differences in the CEL added by customers are …. For instance, !(a == b) is the same as (a != b), and !(a > b) is the same as (a <= b).

With each expression broken down, parsed, and normalized, we need to do the actual match.
Hashmaps & B-Trees FTW
Initially, we tried some fancy ways to match equalities, such as aggregate trees, but we found simple hashmaps work best for string equality, while B-trees work best for numbers (we're exploring roaring bitmaps on the hash front, too).
Our matching engine is a simple yet effective lookup for string equality matching within expressions. It's all written in our open source expr repository in Go. Here's how it works its magic:
- All strings from expressions are added to a hashmap, pointing to the ExpressionPart they match.
- When an event comes in, all its strings are stored in a hashmap, linking them to the ExpressionPart they match.
- Strings are hashed using xxhash for a quick, collision-free lookup while keeping memory usage in check.
- The engine only supports string equality, so it's blazing fast and doesn't mess around with complex operations.
- Each ExpressionPart represents a potential expression match to evaluate.
We run through those in-memory indexes to get a filtered list of expressions. Almost every time, there will be exactly one match, cutting out all the work to match billions of expressions. The match can now happen in milliseconds.
From Years to Milliseconds
Event processing at scale isn't easy. Layering on a multi-tenant system with hundreds of thousands of events per second and short-lived event matching expressions and it gets more complicated. Nothing can wait minutes, let alone years. These refactors and optimizations had to happen to ensure our users' code executed quickly with low latency.
Rethinking how we match expressions to focus on performance means users can continue to scale up their event usage without worrying about timeouts and without us worrying about overstretching resources. If you're interested in trying this out for yourself, then reach out to chat or sign up for Inngest to get started.
Help shape the future of Inngest
Ask questions, give feedback, and share feature requests
Join our Discord!